トップIT企業にソフトウェアエンジニアとして就職するためのプログラミング能力
Google, Apple, Microsoft, Amazon, Facebook, Twitter, IndeedなどのトップIT企業のコーディング面接で要求されるプログラミング能力について紹介します。これらの外資IT企業では、面接でホワイトボードでのコーディングが要求されます。私はこれまでに上記企業を含む数社で十数回ほどコーディング面接を経験しました。その経験を元にして記述しましたので、これらの企業に入社したい人にはある程度有用な記事になっていると思います。
日系企業だと、楽天,Line、リクルート、サイバーエージェントなども選考過程にプログラミングテストがありますが、外資企業とは少し出題形式が違います。おまけとしてそれぞれ簡単に紹介します。なお、ここで紹介しているプログラムは実装の一例に過ぎませんので悪しからず。
この記事を読む前に
この記事を読み進めるために、最小限のレベルとして、配列(Array)や文字列(String)の取り扱い、オブジェクト指向(Class)、オーダー表記についての理解が求められます。まだ十分ではないと感じる人は、以下のサイトで勉強しておきましょう。
求められる水準について
基本的には、トップIT企業といえどそこまで難しい問題はでません。面接官でも赤黒木などの正確な実装は覚えていないということと、面接時間中にそのような難しいアルゴリズムを実装する時間がないということがその理由でしょう。しかし、コンピュータサイエンスにおける基本的な事柄は網羅しておく必要があります。もっとも大事になってくるのはデータ構造とアルゴリズムです。出題された問題に対して、計算時間とメモリ使用量の観点から、最も優れたデータ構造を選び出し、高速なアルゴリズムを実装するというのが基本的な流れです。ただし、いきなり最適解を出す必要はなく、初めはブルートフォース(全探索)のようなアプローチで実装し、徐々に最適化していくという形でも問題ないでしょう。重要なことは、制限時間内に解を見つけ出すことです。また面接官が一緒に働きたいかということも重要なポイントなので、コミュニケーション能力がある程度要求されることはもちろんです。問題がすごく難しいと思ったら、面接官と話し合いながら進めましょう。きっと突破口はあります。
コツ
- 的を得た質問をすることを見ている面接官もいます。問題が曖昧だと思ったら積極的に質問しましょう。
- 今までプログラミングはコンピュータの補完やコピペに頼っていた人がいきなりホワイトボードでコーディングするのはハードルが高いです。紙とペンで練習しておきましょう。
- よいプログラムを書きましょう。バグが入る隙をなくし、保守や拡張がしやすいように心がけます。コードが長くなりそうだったら、モジュールに分割しましょう。
- 競技プログラミングはいい練習問題になるでしょう。AtCoderやTopCoderなどをやると力がつきます。
データ構造
データ構造について、実装まで踏み込んで知っておくことは非常に重要です。計算時間とメモリの消費量についてはどのようなデータ構造を使っているかに依存するからです。また、基本的なデータ構造を変形したものを実装するというような問題も出題されます。この記事ではプログラムは基本的にJavaで記述しています。面接時に利用するプログラミング言語はなんでも大丈夫です。ただ、クラスのない言語はやめておくべきでしょう。オブジェクト指向の考え方を身につけておく必要は大いにあります。必ず知っておくべきデータ構造として、連結リスト(Linked List)、スタック(Stack)、キュー(Queue)、ハッシュテーブル(Hashtable)などが挙げられます。これのデータ構造を実装を踏まえつつ、解説します。上から読んでいくと、すべてのデータ構造をいちから理解できるようになっています。
事前準備
この記事では、以下のクラスが定義されているとして、進めていきます。これらのクラスは、これから定義するデータ構造の実装の元になります。
/* 様々なデータ構造の元になるNodeクラス、 自身と同じクラス型のnextフィールドを持つ */ class Node<T>{ Node<T> next; T data; public Node(T data){ next = null; this.data = data; } } /* データ構造にサイズと空判定を提供するContainerクラス データ構造ごとに空判定を実装するのが面倒なので、 サイズを保持する必要があるデータ構造はこれを継承する*/ abstract class Container{ private int size = 0; public int getSize() { return size; } /* サイズが0の時trueを返す */ public boolean isEmpty() { return getSize() == 0; } protected void increment() { size++; } protected void decrement() { size--; } }
連結リスト(Linked List)
連結リストはデータの挿入や、削除が高速に実行できるデータ構造です。また、可変長のデータを扱えます。ただし、データの取得は少し時間がかかります。挿入や削除が高速に実行できる理由は、配列と違い、データがメモリ上に並んでいないため、シフトの必要がないからです。それぞれのデータは前のデータの情報のみを保持しています。そのため、単方向連結リスト(Single Linked List)とも呼ばれます。
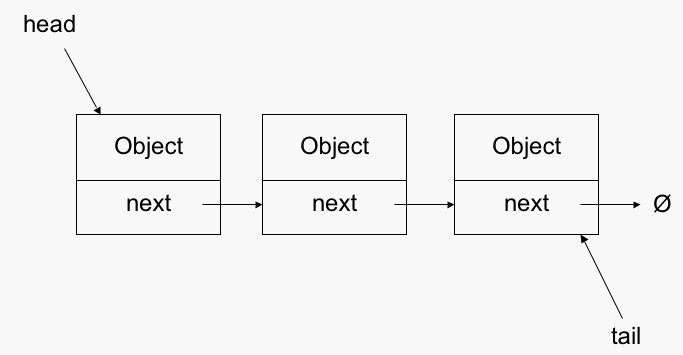
class LinkedList<T> extends Container{ /* 先頭のノード ここからたどることで、全データにアクセスできる */ Node<T> root; /* 末尾にデータを追加する O(n) */ public void appendToTail(T data){ if (isEmpty()){ root = new Node<>(data); }else { /* 末尾のノードを探索する際に、先頭ノードを置き換えないようにする */ Node<T> node = root; while (node.next != null) { node = node.next; } node.next = new Node<>(data); } increment(); } /* 先頭に挿入する O(1) */ public void append(T data){ Node<T> node = new Node<>(data); node.next = root; root = node; increment(); } /* データを削除する O(n) */ public boolean remove(T data){ if (isEmpty()){ return false; } else if (root.data.equals(data)){ /* 先頭ノードを削除(次のノードに置き換える) */ root = root.next; decrement(); return true; }else { /* 引数と等しいノードを探索する O(n) */ Node<T> node = root; while (!node.next.data.equals(data) && node.next != null) { node = node.next; } if (node.next == null) { return false; } else { /* ノードを1つ削除し、次の次のノードに置き換える O(1) */ node.next = node.next.next; decrement(); return true; } } } /* IteratorクラスはNodeを進める機能をユーザーに提供する */ static class Iterator<TI>{ Node<TI> node; public Iterator(Node<TI> node){ this.node = node; } public TI next(){ if (hasNext()) { TI data = node.data; node = node.next; return data; }else{ return null; } } public boolean hasNext(){ return node != null; } } public Iterator<T> iterator(){ return new Iterator<>(root); } /* テスト */ public static void main(String[] av){ LinkedList<Integer> list = new LinkedList<>(); list.appendToTail(1); list.appendToTail(2); list.appendToTail(3); list.remove(2); LinkedList.Iterator<Integer> ite = list.iterator(); assert ite.next() == 1; assert ite.next() == 3; assert ite.next() == null; } }
スタック(Stack)
スタックは基本的なデータ構造の1つで、データを後入れ先出し(LIFO: Last In First Out)の構造で保持するものです。スタックはお皿を積み上げることを想像するとわかりやすいです。お皿を積み上げる時は、上に積み上げていきます(追加)。積み上げたお皿を取るときは、一番上からしか取れません(取り出し)。

class Stack<T> extends Container { Node<T> top = null; /* データを追加する O(1) */ public void push(T data){ Node<T> n = new Node<>(data); n.next = top; top = n; increment(); } /* データを取り出す O(1) */ public T pop(){ if (isEmpty()){ return null; } T data = top.data; top = top.next; decrement(); return data; } /* データを見る O(1) */ public T peek(){ if (isEmpty()){ return null; } return top.data; } /* テスト */ public static void main(String[] av){ Stack<Integer> stack = new Stack<>(); stack.push(1); stack.push(2); assert stack.pop() == 2; assert stack.pop() == 1; assert stack.peek() == null; } }
キュー(Queue)
キューは基本的なデータ構造の1つで、データを先入れ先出し(FIFO: First In First Out)の構造で保持するものです。キューは待ち行列を想像するとわかりやすいです。行列に並ぶときは、一番後ろに並びます(追加)。行列からでるのは、一番前に並んでいる人だけです(取り出し)。

class Queue<T> extends Container{ Node<T> tail = null; Node<T> head = null; /* データを追加する O(1) */ public void enqueue(T data){ Node<T> n = new Node<>(data); if (tail == null){ head = tail = n; }else { head.next = n; head = head.next; } increment(); } /* データを取り出す O(1) */ public T dequeue(){ if (isEmpty()){ return null; } T data = tail.data; tail = tail.next; decrement(); return data; } /* データを見る O(1) */ public T peek(){ if (isEmpty()){ return null; } return tail.data; } /* テスト */ public static void main(String[] av){ Queue<Integer> queue = new Queue<>(); queue.enqueue(1); queue.enqueue(2); assert queue.dequeue() == 1; assert queue.dequeue() == 2; assert queue.peek() == null; } }
可変長配列(ArrayList)
可変長配列は要素数によって自動的にサイズが拡張する配列です。動的配列とも言われます。データのアクセスが高速なため,さまざまなデータ構造やアルゴリズムを記述する際に、有用なデータ構造です。どのように配列を拡張させるかというのが問題ですが、一般的には非常に簡単です。要素数が制限まできたら、今までの要素数の2倍の大きさの配列を新たに確保して、今までのデータをコピーするだけです。データを削除すると左シフトが必要になるため,時間がかかります。
class ArrayList<T> extends Container{ static final int INITIAL_CAPACITY = 1024; int capacity = INITIAL_CAPACITY; Object[] data; public ArrayList(){ data = new Object[capacity]; } /* 要素の追加 O(1) 拡張処理はめったに起こらないので、ならしでO(1) */ public void add(T data){ if (capacity <= getSize()){ expandCapacity(); } this.data[getSize()] = data; increment(); } private void expandCapacity(){ Object[] larger_data = new Object[capacity*2]; System.arraycopy(this.data, 0, larger_data, 0, capacity); capacity *= 2; this.data = larger_data; } /* 要素の取得 O(1) */ @SuppressWarnings("unchecked") public T get(int i){ if (i < 0 || getSize() <= i) { return null; } return (T)data[i]; } /* 要素の削除 O(n) */ public boolean removeAt(int index){ if (getSize() < index || index < 0){ return false; } /* 穴を埋めるために左シフトが必要 */ leftShift(index); decrement(); return true; } private void leftShift(int idx){ for ( int i = idx; i < getSize()-1; i++){ data[i] = data[i+1]; } data[getSize()-1] = null; } @Override public String toString() { StringBuilder sb = new StringBuilder(); sb.append('['); for ( int i = 0; i < getSize(); i++){ sb.append(data[i]); sb.append(' '); } sb.append(']'); return sb.toString(); } public static void main(String[] av){ ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(-3); list.removeAt(1); assert list.get(0) == 1; assert list.get(1) == -3; assert list.get(2) == null; } }
ArrayStack
可変長リスト(ArrayList)を継承すると、簡単にStackを実装することができます。
class ArrayStack<T> extends ArrayList<T> { public ArrayStack(){ super(); } public void push(T data){ super.add(data); } public T pop(){ if (isEmpty()){ return null; } decrement(); return super.get(getSize()); } public T peek(){ return super.get(getSize()-1); } }
ハッシュテーブル(Hashtable)
ハッシュテーブル (hashtable) は、キーと値の組を複数個格納し、キーに対応する値をすばやく参照するためのデータ構造です。あらゆるアルゴリズムで応用が効くため,めちゃ重要なデータ構造です。実際にどうやって,効率的にキーと値を保持するのかというところですが,一般的にはハッシュコードというキーから得られる整数値(ハッシュ値とも)を使って値を配列にマッピングします。ハッシュコードの生成方法を設計するときの条件は,同一のキーからは同一のハッシュコードが得られればそれでいいのです。つまり,2つ以上のキーが同じハッシュコードを持つことが許されます。このハッシュコードを配列の添字に対応させて,その位置に値を保持することで効率的な値の保持を実現するわけです。このような方法では,ハッシュコード次第で非常に大きな配列が必要になります。そのため実用上は小さい配列を使い,ハッシュコードを配列のサイズで割った余りを添字として使います。ここで問題となるのが,異なるキーにおける添字の衝突です。その簡単な解決法は,配列の要素をリストにすることです。値とキーのペアを対応する添字のリストに追加していきます。キーからの値の取得時には,対応する添字のリストからキーの全探索を行います。ハッシュコードをなるべく一様に分布させることで効率的な探索(ならしでO(1))ができることがわかると思います。逆に,全てのキーのハッシュコードを同じ整数値にした場合,探索時間はO(n)になってしまうでしょう。また、ハッシュテーブルのサイズが要素の数よりも少なくなってしまう場合、効率的な探索が行えなくなることがあります。そのような場合、ハッシュテーブルのサイズを拡張し、ハッシュを再構成(リマップ)することで、目的のハッシュテーブルを得ることができます。ハッシュテーブルは紹介してきた上記のデータ構造を組み合わせるだけで実装できます。
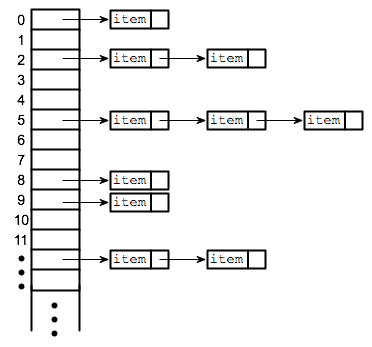
class HashMap<K,V> { static final int TABLE_SIZE = 512; private class KeyValuePair<K0,V0>{ K0 key; V0 value; public KeyValuePair(K0 k, V0 v){ key = k; value = v; } } ArrayList<LinkedList<KeyValuePair<K,V>>> table = new ArrayList<>(); public HashMap(){ for (int i = 0; i < TABLE_SIZE; i++ ){ table.add(new LinkedList<>()); } } /* 値のマッピング O(1) */ public void put(K key, V value){ /* ハッシュ値の剰余に対応するリストを得る */ LinkedList<KeyValuePair<K,V>> list = table.get(key.hashCode() % TABLE_SIZE); LinkedList.Iterator<KeyValuePair<K,V>> ite = list.iterator(); /* キーの値を全探索 */ while(ite.hasNext()){ KeyValuePair<K, V> kv = ite.next(); if (kv.key.equals(key)){ /* すでに値がマッピングされていたら、値を更新して終了する */ kv.value = value; return; } } /* キーと値のペアをリストに挿入する */ list.append(new KeyValuePair<>(key, value)); } /* 値の取得 O(1) */ public V get(K key){ /* ハッシュ値の剰余に対応するリストを得る */ LinkedList<KeyValuePair<K,V>> list = table.get(key.hashCode() % TABLE_SIZE); LinkedList.Iterator<KeyValuePair<K,V>> ite = list.iterator(); /* キーの値を全探索 */ while(ite.hasNext()){ KeyValuePair<K, V> kv = ite.next(); if (kv.key.equals(key)){ return kv.value; } } return null; } public static void main(String[] av){ HashMap<Integer, String> hm = new HashMap<>(); hm.put(1, "one"); hm.put(2, "tw"); hm.put(2, hm.get(2)+"o"); hm.put(100, "hundred"); assert hm.get(1).equals("one"); assert hm.get(2).equals("two"); assert hm.get(100).equals("hundred"); } }
ハッシュ集合(HashSet)
高速に値の検索ができるハッシュ集合は、上記のHashMapを継承すると簡単に実装できます。ただし、少しメモリがむだになります。
class HashSet<T> extends HashMap<T, Boolean>{ public HashSet(){ super(); } public void add(T data){ super.put(data, true); } public boolean contains(T data){ return super.get(data) != null; } }
二分探索木(Binary Tree)
二分探索木の実装を見る前に、アルゴリズムの章について見ておくと理解しやすくなると思います。二分探索木は「左の子孫の値 ≤ 親の値 ≤ 右の子孫の値」という制約を持つ二分木です。二分探索木は値の取得、値の挿入、値の削除が高速(logN)に行えるデータ構造です。ただし、それは木が平衡化されている場合に限ります。平衡化アルゴリズムは赤黒木などいくつかありますが、実際にコーディング面接で実装することはないでしょう。
class BinaryNode<T>{ BinaryNode<T> left, right; T data; public BinaryNode(T data){ left = right = null; this.data = data; } } class BinarySearchTree<T extends Comparable<T>> extends Container{ BinaryNode<T> root = null /* 値の挿入 O(logN) */ public void insert(T data){ if (root == null){ root = new BinaryNode<>(data); increment(); }else { insert(data, root); } } private void insert(T data, BinaryNode<T> node){ if (node.data.compareTo(data) <= 0){ if(node.right == null){ node.right = new BinaryNode<>(data); increment(); }else{ insert(data, node.right); } }else{ if(node.left == null){ node.left = new BinaryNode<>(data); increment(); }else{ insert(data, node.left); } } } /* 値の探索 O(logN) */ public boolean search(T data){ return search(data, root); } private boolean search(T data, BinaryNode<T> node){ if (node == null){ return false; }else if (node.data.compareTo(data) == 0){ return true; }else{ if (node.data.compareTo(data) <= 0){ return search(data, node.right); }else { return search(data, node.left); } } } }
アルゴリズム
アルゴリズムには探索、ソーティング、組み合わせ、動的計画法、など多数あります。多くのアルゴリズムは紹介してきた上記のデータ構造を使用した実装になるとおもいますのでデータ構造についての理解は必須といえます。二分探索(Binary Search)
二分探索は必ず知っておくべき重要なアルゴリズムの1つです。二分探索はソートされた配列から、O(logN)の時間で目的の要素を探索することができます。配列上のデータを探索する際に、中央の値と探索したい値との大小関係を用いて、探索したい値が中央の値の右にあるか、左にあるかを判断して、片側にはないことを確認し、探索範囲を狭めていくことで、高速な探索が実現されます。実装には再帰的な方法とループでの方法がありますが、ここでは両方紹介します。
class BinarySearch { /* ループでの実装:見つかったら添字を返す O(logN) */ public static int binarySearch(int[] array, int target){ int left = 0; int right = array.length-1; while (left <= right){ /* 中央の値を見る */ int mid = (left+right)/2; int value = array[mid]; if (target < value){ /* 探索したい値が左にある:右を狭める */ right = mid - 1; }else if (value < target){ /* 探索したい値が右にある:左を狭める */ left = mid + 1; }else{ /* 探索したい値が見つかった */ return mid; } } return -1; } /* 再帰での実装:見つかったら添字を返す O(logN) */ public static int binarySearchRecursive(int[] array, int target){ return binarySearchRecursive(array, target, 0, array.length-1); } private static int binarySearchRecursive(int[] array, int target, int left, int right){ if (right < left){ return -1; } int mid = (left+right)/2; int value = array[mid]; if (target < value){ return binarySearchRecursive(array, target, left, mid-1); }else if (value < target){ return binarySearchRecursive(array, target, mid+1, right); }else{ return mid; } } public static void main(String[] av){ int[] array = {1, 5, 9}; assert binarySearch(array, 1) == 0; assert binarySearch(array, 5) == 1; assert binarySearch(array, 9) == 2; assert binarySearch(array, 3) == -1; } }
グラフ探索(Graph Traversal)
グラフ探索アルゴリズムには大きく分けて、同じレベルのノードから順に見ていく幅優先探索と末端ノードからバックトラックする深さ優先探索の2種類があります。幅優先探索は、最短距離を計算するときなどに有用で、深さ優先探索は全探索などに使われます。また、グラフ探索アルゴリズムは単にデータ構造の探索というだけでなく、複雑な問題をグラフの形に変形し、そこにグラフ探索アルゴリズムを適用するといった使い方ができます。例えば、ハノイの塔などの問題はグラフの形に変形することで、深さ優先探索で解くことができます。
幅優先探索(BFS: Breadth First Search)
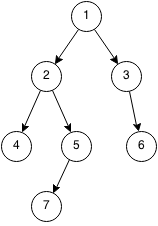
幅優先探索は根ノードから始まり、隣接した全てのノードを浅いノードから順々に見ていく方法です。幅優先探索の実装にはキューを使います。
public void BFS(BinaryNode<T> root){ if (root == null) return; Queue<BinaryNode<T>> queue = new Queue<>(); queue.enqueue(root); while (!queue.isEmpty()){ BinaryNode<T> node = queue.dequeue(); visit(node); if (node.left != null) { queue.enqueue(node.left); } if (node.right != null){ queue.enqueue(node.right); } } }
深さ優先探索(DFS: Depth First Search)
深さ優先探索には3種類の探索方法があります。それぞれ必要な場面が異なるため、すべて把握しておくと心強いです。実装の方法は、再帰的な方法と、スタックを用いる方法の二通りあります。再帰的な方法は実装は簡単ですが、高速化などの最適化をするのが難しいため、スタックを用いるほうが自由度があると思います。ここでは両方紹介します。
深さ優先探索(Depth First Search):前順(pre-order)
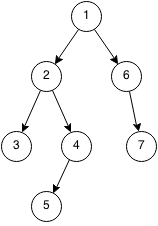
前順(pre-order)はノードを初めに評価してから他の枝に進む方法です。考え方がシンプルなため、前順での深さ優先探索は3種類のなかでは最も簡単に実装できます。使用場面の多くは全探索などになるかと思います。
public void preOrderRecursiveDFS(BinaryNode<T> node){ if (node == null) return; visit(node) preOrderRecursiveDFS(node.left); preOrderRecursiveDFS(node.right); } public void preOrderDFS(BinaryNode<T> root){ if (root == null) return; Stack<BinaryNode<T>> stack = new Stack<>(); stack.push(root); while (!stack.isEmpty()){ BinaryNode<T> node = stack.pop(); visit(node); if (node.right != null){ stack.push(node.right); } if (node.left != null){ stack.push(node.left); } } }
深さ優先探索(Depth First Search):中順(in-order)
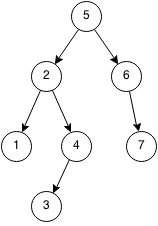
中順(in-order)は、ノードの評価が最左が初めで、最右が最後になります。中順により、例えば二分探索木のすべての要素をソートされた形で表示することができます。また、ハノイの塔の解法は中順になっています。
public void inOrderRecursiveDFS(BinaryNode<T> node){ if (node == null) return; inOrderRecursiveDFS(node.left); visit(node); inOrderRecursiveDFS(node.right); } public void inOrderDFS(BinaryNode<T> root){ if (root == null) return; Stack<BinaryNode<T>> stack = new Stack<>(); HashSet<BinaryNode<T>> visited = new HashSet<>(); stack.push(root); while(!stack.isEmpty()){ BinaryNode<T> n = stack.peek(); while(n.left != null && !visited.contains(n.left)){ n = n.left; stack.push(n); } BinaryNode<T> node = stack.pop(); visit(node); visited.add(node); if (node.right != null && !visited.contains(node.right)){ stack.push(node.right); } } }
深さ優先探索(Depth First Search):後順(post-order)

後順はとにかく1番深い所から順にノードを見ていく方法です。逆ポーランド記法などで応用ができます。
public void postOrderRecursiveDFS(BinaryNode<T> node){ if (node == null) return; postOrderRecursiveDFS(node.left); postOrderRecursiveDFS(node.right); visit(node); } public void postOrderDFS(BinaryNode<T> root){ if (root == null) return; Stack<BinaryNode<T>> stack = new Stack<>(); HashSet<BinaryNode<T>> visited = new HashSet<>(); stack.push(root); while (!stack.isEmpty()){ BinaryNode<T> n = stack.peek(); while((n.left != null && !visited.contains(n.left)) || (n.right != null && !visited.contains(n.right))){ if ( n.left != null && !visited.contains(n.left)){ n = n.left; }else{ n = n.right; } stack.push(n); } BinaryNode<T> node = stack.pop(); visit(node); visited.add(node); } }
必ず知っておくべき標準クラス
実際のコーディング面接では、アルゴリズムの問題でデータ構造を1から実装すると時間がなくなってしまうので、既存のものを使いましょう。。Javaの場合、最低限以下のデータ構造はおさえておきます。
- 可変長配列(array list)
ArrayList<Integer> list = new ArrayList<>(); list.add(2); int two = list.get(0);
- スタック(stack)
Stack<Integer> list = new Stack<>(); stack.push(2); int two = stakc.pop();
- キュー(queue)
Queue<Integer> queue = new Queue<>(); queue.add(2); int two = queue.poll();
- ハッシュテーブル(hashtable)
HashMap<String, Integer> map = new HashMap<>(); map.put("two", 2); int two = map.get("two"); map.containsKey("three"); // false
日系企業でのプログラミングテスト
詳しいことはかけませんが、参考程度にはなるかと思います。
楽天
楽天のプログラミングテストは面接前に一度だけ行なわれます(40分程度)。自分のPCを使ってオンラインで問題を1問解きます。データ構造とアルゴリズムに関する問題が出題されます。問題の難易度はそこまで難しいものではありません。この記事を理解したならば,問題なく解けるかと思います。
リクルート
リクルートのプログラミングテストは面接前に一度行なわれます(2時間程度)。自分のPCを使ってオンラインで問題を何問か解きます。リクルートのプログラミングテストはAtCoderに依頼して作られているため,事前にAtCoderの問題を解いておくことで対策することができます。最後の問題は割とむずかしいです。Indeedの場合,これに加えてホワイトボードでのコーディング面接が3回あります(3時間程度)。
Line
Lineのプログラミングテストは面接前に一度行なわれます(1時間~1時間半程度)。自分のPCを使ってオンラインで問題を何問か解きます。テスト中にインターネットを使って検索することができます。インターン選考では,短期間でスマートフォンアプリケーションなどを作ることが要求されることがあります。
サイバーエージェント
サイバーエージェントのプログラミングテストは面接前に一度だけ行なわれます(2時間程度)。自分のPCを使ってオンラインで問題を何問か解きます。サーバーエージェントの問題はサーバーにAPIを実装するなど,実践的な問題が多いです。Linux, データベース, サーバーサイドなどの知識が重要になります。